This time I heard it, I got a feeling that the whole stereo image is moved to the left. I confirmed my feelings by checking the left / right levels in the multimeter:
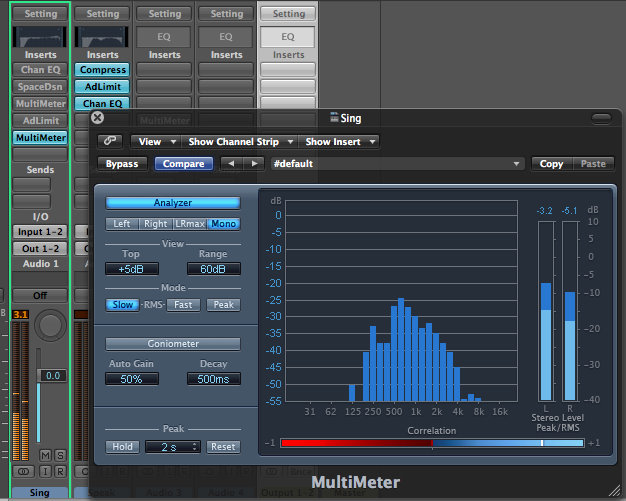
To correct it, I panned the stereo track by 11 points to the right. When I was trying to find the right pan value for the track, I found out that when I move my head sideways, the stereo image changes a lot, like it was missing 'middle'. To change this unpleasant feeling, I decided to send the whole thing to the mono bus. This was also a possibility to deepen the spatial feeling of the record by adding a bit of artificial reverb on the stereo track and EQing the mono track so that it would sound 'closer'.
This set-up resulted in nicely balanced sound, with good stereo spread and warm, pleasant centre.
The processors I used on the stereo track:
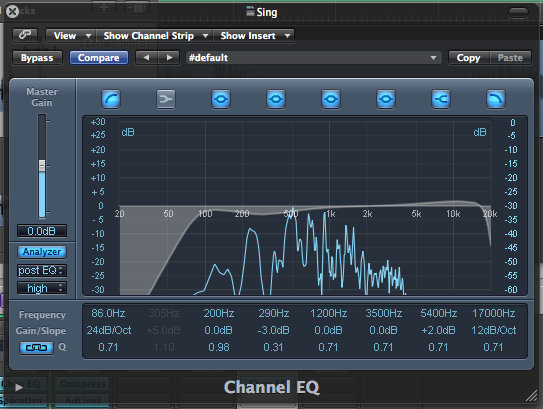
EQ:
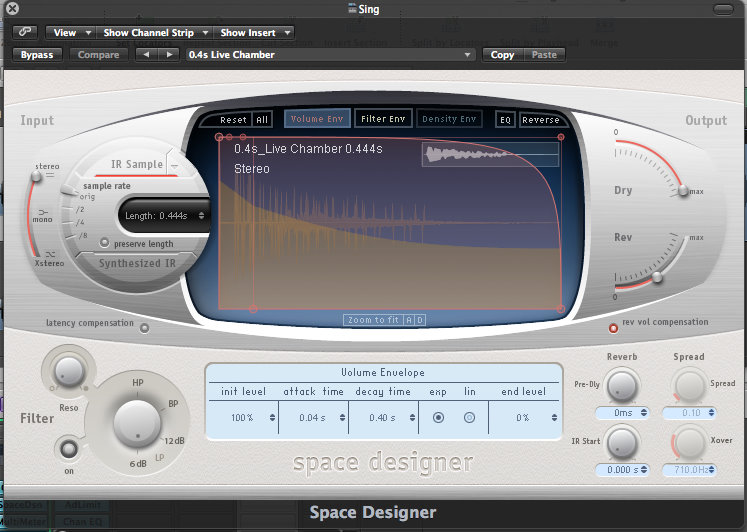
Space Designer – Preset 'Live Chamber', 0.444s. Dry: Max, Rev: -12dB (barely audible, adds space but not too much).
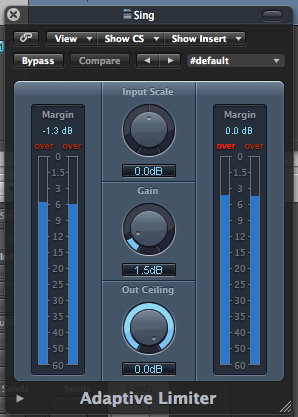
Limiter: Set up so that it doesn't activate unless they clap. I used it just to bring volume up to acceptable level.
The sound from stereo track was sent to Bus1 which I set to be mono. The only processor on the Bus1 was EQ: Low Cut @ 38Hz, 24dB/oct, Top Cut @ 1360 Hz, 6dB/oct.
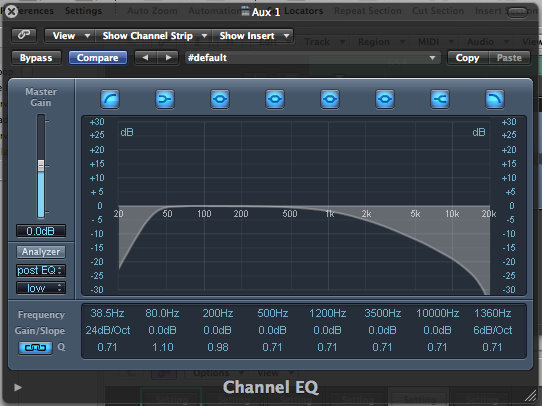
The amount of the mono bus in the mix was reduced by 4.3dB.
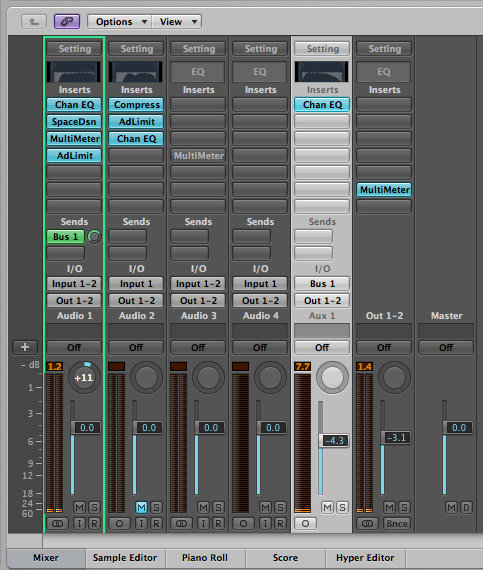
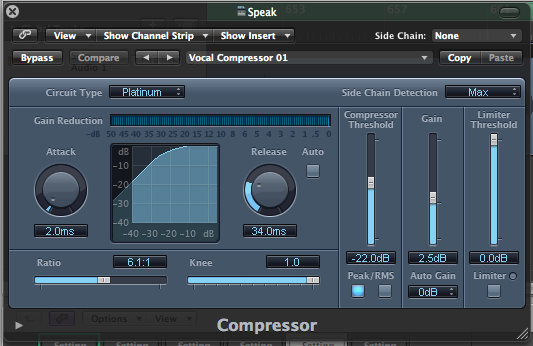
For the parts where the course leader was speaking between songs, I had to use completely different set of processors. Keeping the dynamics of the sound is not that important for those moments, as they mostly consist of speech. Therefore, I was free to use quite heavy compression: Threshold of -22dB, ratio 6.1:1, attack 2ms, release 34ms.
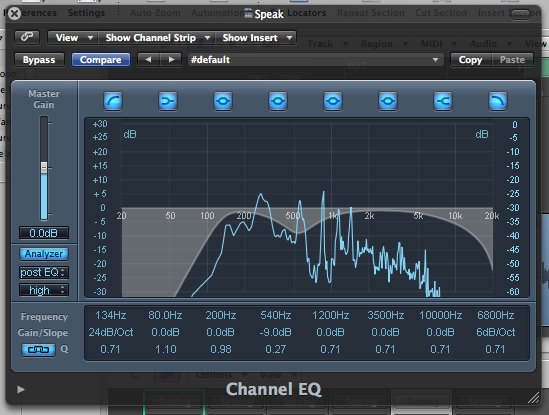
I also used EQ:
Onto such prepared track, I pasted regions of speech cut out from the stereo track. I cross-faded them to make transitions smoother. This resulted in great improvement of audibility of speech, and let me keep the dynamic changes intact for when they were singing.
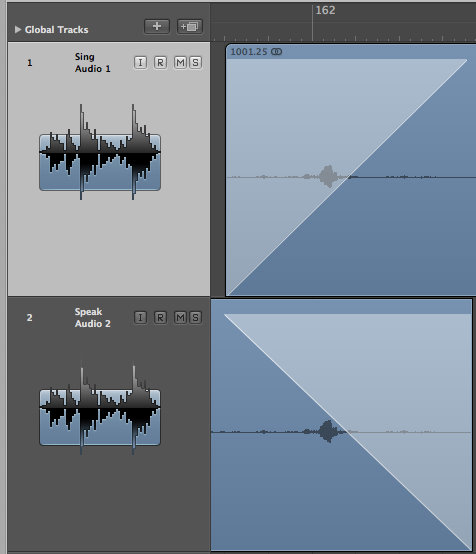
Close-up of the fades
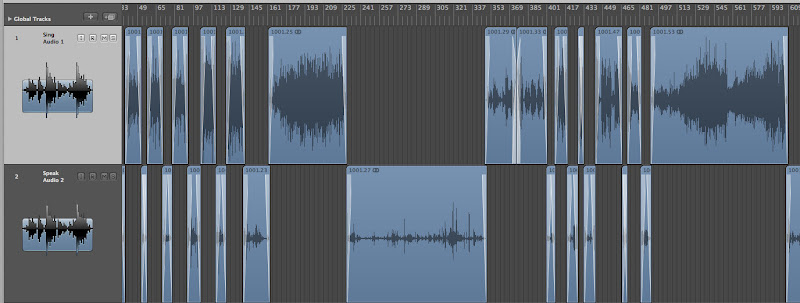
Wide view of the cut track
Now, having everything cut and mixed, I only have to adjust levels of each song and find a smart way of splitting the project into separate tracks.
- Bass cut @ 86 Hz
- Dip by 3db @ 290 Hz
- Top shelf from 5.4kHz up by 2dB
- top cut at 17kHz.

Space Designer – Preset 'Live Chamber', 0.444s. Dry: Max, Rev: -12dB (barely audible, adds space but not too much).

Limiter: Set up so that it doesn't activate unless they clap. I used it just to bring volume up to acceptable level.

The sound from stereo track was sent to Bus1 which I set to be mono. The only processor on the Bus1 was EQ: Low Cut @ 38Hz, 24dB/oct, Top Cut @ 1360 Hz, 6dB/oct.

The amount of the mono bus in the mix was reduced by 4.3dB.

For the parts where the course leader was speaking between songs, I had to use completely different set of processors. Keeping the dynamics of the sound is not that important for those moments, as they mostly consist of speech. Therefore, I was free to use quite heavy compression: Threshold of -22dB, ratio 6.1:1, attack 2ms, release 34ms.

I also used EQ:
- Low cut at 134Hz
- Dip @ 540Hz by 9dB
- High cut @ 6800Hz, 6dB/oct.

Onto such prepared track, I pasted regions of speech cut out from the stereo track. I cross-faded them to make transitions smoother. This resulted in great improvement of audibility of speech, and let me keep the dynamic changes intact for when they were singing.

Close-up of the fades

Wide view of the cut track
Now, having everything cut and mixed, I only have to adjust levels of each song and find a smart way of splitting the project into separate tracks.
